/cdn.vox-cdn.com/uploads/chorus_asset/file/24054838/AMD_Ryzen_7000_Desktop_CPU_Lineup_low_res_scale_4_00x_Custom.png "Microsoft meningkatkan kinerja CPU Ryzen dengan pembaruan Windows 11 terbaru")





Urich Lawson | Gambar Getty
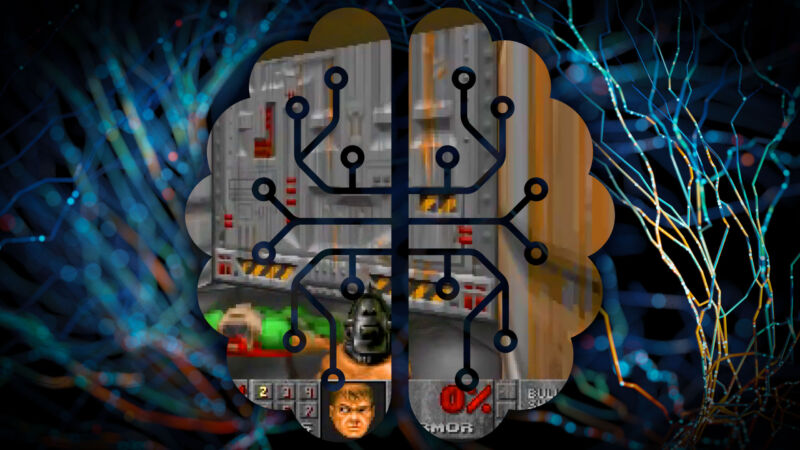
Para peneliti dari Google dan Universitas Tel Aviv membuat penemuan ini pada hari Selasa Mesin Jimmodel AI baru yang secara interaktif dapat mensimulasikan penembak orang pertama klasik tahun 1993 kematian Secara real time menggunakan teknik pembuatan gambar AI yang dipinjam dari Stable Diffusion. Ini adalah sistem jaringan saraf yang dapat bertindak sebagai mesin permainan terbatas, yang dapat membuka kemungkinan baru untuk sintesis video game real-time di masa depan.
Misalnya, alih-alih menggambar bingkai video grafis menggunakan teknik tradisional, game masa depan kemungkinan besar akan menggunakan mesin AI untuk “memvisualisasikan” atau memvisualisasikan grafik secara real-time sebagai tugas prediksi.
““Potensi di sini sungguh menggelikan.” buku Pengembang aplikasi Nick Dubus menanggapi berita tersebut dengan mengatakan: “Mengapa menulis aturan rumit untuk perangkat lunak dengan tangan ketika AI dapat memikirkan setiap piksel untuk Anda?”
GameNGen dilaporkan dapat membuat frame baru dari kematian Game dengan kecepatan lebih dari 20 frame per detik menggunakan unit pemrosesan tensor (TPU) tunggal, sejenis prosesor khusus yang mirip dengan GPU yang dioptimalkan untuk tugas pembelajaran mesin.
Dalam pengujian, kata para peneliti, sepuluh penilai manusia terkadang gagal membedakan klip pendek (1,6 detik dan 3,2 detik) dari video sebenarnya. kematian Cuplikan dan keluaran game dihasilkan oleh GameNGen, yang menangkap cuplikan gameplay sebenarnya sebanyak 58 persen atau 60 persen.
Contoh aksi GameNGen, simulasi Doom secara interaktif menggunakan model gergaji ukir.
Sintesis video game real-time menggunakan apa yang disebut “Presentasi neurologis“Ini bukanlah ide yang sepenuhnya baru,” kata CEO Nvidia Jensen Huang mengharapkan Dalam sebuah wawancara di bulan Maret, mungkin dengan agak berani, dia mengatakan bahwa sebagian besar grafik video game dapat dihasilkan oleh AI real-time dalam waktu lima hingga 10 tahun.
GameNGen juga mengembangkan penelitian sebelumnya di bidang ini, yang dikutip dalam makalah GameNGen, yang meliputi: Model serbaguna Pada tahun 2018, Jimgan pada tahun 2020, dan program Genie Google pada bulan Maret. Sekelompok peneliti universitas juga melatih model kecerdasan buatan (disebut “berlian“) untuk meniru video game Atari kuno menggunakan model difusi awal tahun ini.
Ada juga penelitian yang sedang berlangsung tentang “Model serbaguna“atau”Simulator dunia“Cenderung,” biasanya dikaitkan dengan model sintesis video AI seperti Gen-3 Alpha dari Runway dan Sora dari OpenAI, dalam arah yang sama. Misalnya, saat debut Sora, OpenAI menampilkan video demo generator AI simulasi Minecraft.
Difusi adalah kuncinya
Dalam makalah penelitian pracetak yang berjudul “Model difusi adalah mesin permainan waktu nyataPenulis Danny Valevsky, Yaniv Levithan, Moab Arar, dan Shlomi Frukhter menjelaskan cara kerja GameNGen. Sistem mereka menggunakan versi modifikasi dari Stable Diffusion 1.4, model penerbitan montase gambar yang dirilis pada tahun 2022 yang digunakan orang untuk menghasilkan gambar yang dihasilkan AI.
“Ternyata jawaban dari pertanyaan ‘apakah bisa berjalan’. kematian“?” Ya untuk model difusi, buku Direktur Riset Stabilitas AI Tanishq Mathew Abraham, yang tidak terlibat dalam proyek penelitian.
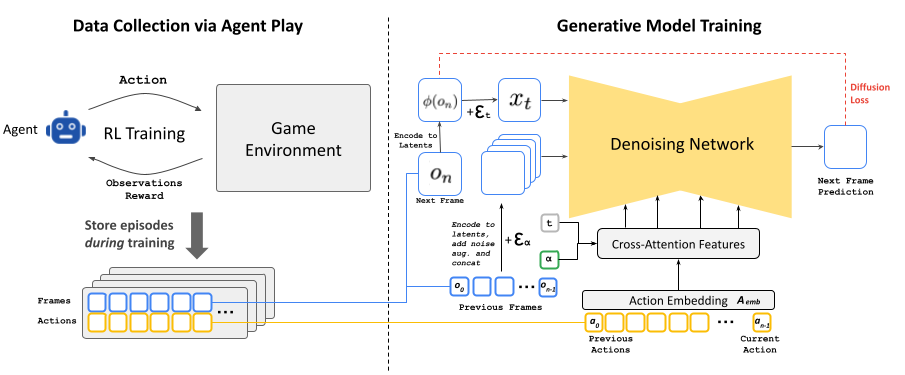
Sambil dipandu oleh masukan pemain, model difusi memprediksi keadaan permainan berikutnya dari keadaan sebelumnya setelah dilatih berdasarkan gambaran ekstensif dari keadaan permainan. kematian Di tempat kerja.
Pengembangan GameNGen melibatkan proses pelatihan dua tahap. Pertama, peneliti melatih agen pembelajaran penguatan untuk bermain kematiandengan sesi gameplay direkam untuk membuat kumpulan data pelatihan yang dibuat secara otomatis – cuplikan yang kami sebutkan. Mereka kemudian menggunakan data tersebut untuk melatih model difusi stabil khusus.
Namun, penggunaan Difusi Stabil menimbulkan beberapa masalah grafis, seperti yang dicatat oleh para peneliti dalam abstrak mereka: “Autoencoder terlatih dari Stable Diffusion v1.4, yang memampatkan patch 8 x 8 piksel menjadi 4 saluran laten, menghasilkan artefak yang bermakna saat memprediksi bingkai permainan, yang memengaruhi detail kecil, terutama bilah HUD bagian bawah.”
Contoh aksi GameNGen, simulasi Doom secara interaktif menggunakan model gergaji ukir.
Namun ini bukan satu-satunya tantangan. Mempertahankan kejelasan dan konsistensi visual dari waktu ke waktu (sering disebut “koherensi temporal” dalam ruang video AI) dapat menjadi sebuah tantangan. Peneliti GameNGen mengatakan bahwa “mensimulasikan dunia interaktif tidak terbatas pada pembuatan video yang sangat cepat,” tulis mereka dalam makalah mereka. “Persyaratan untuk beradaptasi hanya dengan serangkaian tindakan masukan yang tersedia sepanjang periode pembangkitan mematahkan beberapa asumsi struktur model difusi yang ada,” termasuk berulang kali menghasilkan kerangka baru berdasarkan kerangka sebelumnya (disebut “autoregresi”), yang dapat menyebabkan ketidakstabilan dan cepat. penurunan kualitas dunia yang dihasilkan seiring berjalannya waktu.

“Communication. Music lover. Certified bacon pioneer. Travel supporter. Charming social media fanatic.”
More Stories
Microsoft meningkatkan kinerja CPU Ryzen dengan pembaruan Windows 11 terbaru
Fitur tampilan baru pada Pixel 9 membuat penggunaannya dengan tangan basah menjadi lebih mudah
“Akumulasi daging dalam jumlah besar” dan frasa meresahkan lainnya dari inspeksi USDA terhadap pabrik kepala babi